SQLiteやDuckDBで日本語全文検索をVaporettoを組み込んで実現する
各種エージェントの台頭により、サーバレスに動作しローカルファイルとして保存でき、永続化可能な組み込みデータベースのSQLiteやDuckDBへの注目を感じる昨今ですね。これらDBでの全文検索(FTS)の日本語対応ってどんなものなのだろうかと調べると、trigram での検索はできるものの、日本語語彙に特化した検索は標準できないようでした。
Linderaを使うアプローチもあるようですが、今回は Rust で実装されている軽量高速なトークナイザの Vaporetto を組み込んで動く拡張機能を作ってみました。
- SQLite + Vaporetto
- DuckDB + Vaporetto
Vaporetto は、点予測法で文字境界を線形分類モデルで判定するため、辞書なしモデル(辞書ありモデルもある)で利用可能なため、サイズを小さく保つこともできるので用途によっては便利そうですね。ので、Web ブラウザー上で完結する、DuckDB + Vaporetto の組み合わせで bm25 関連度スコアでソートする全文検索を行える技術デモを作ってみました。ただ対象テキストの件数が少ないと、全文検索(件数が増えても高速に検索が可能)やbm25(単語の出現回数や文章長を加味)の嬉しさが少ないのですが…。
また例えば、この blog(secon.dev) の記事検索を SQLite + FTS5 + vaporetto の組み合わせで試しに作ってみたところ、約2700記事の bm25 検索で、大体3ms前後の速度で検索が可能になりました。
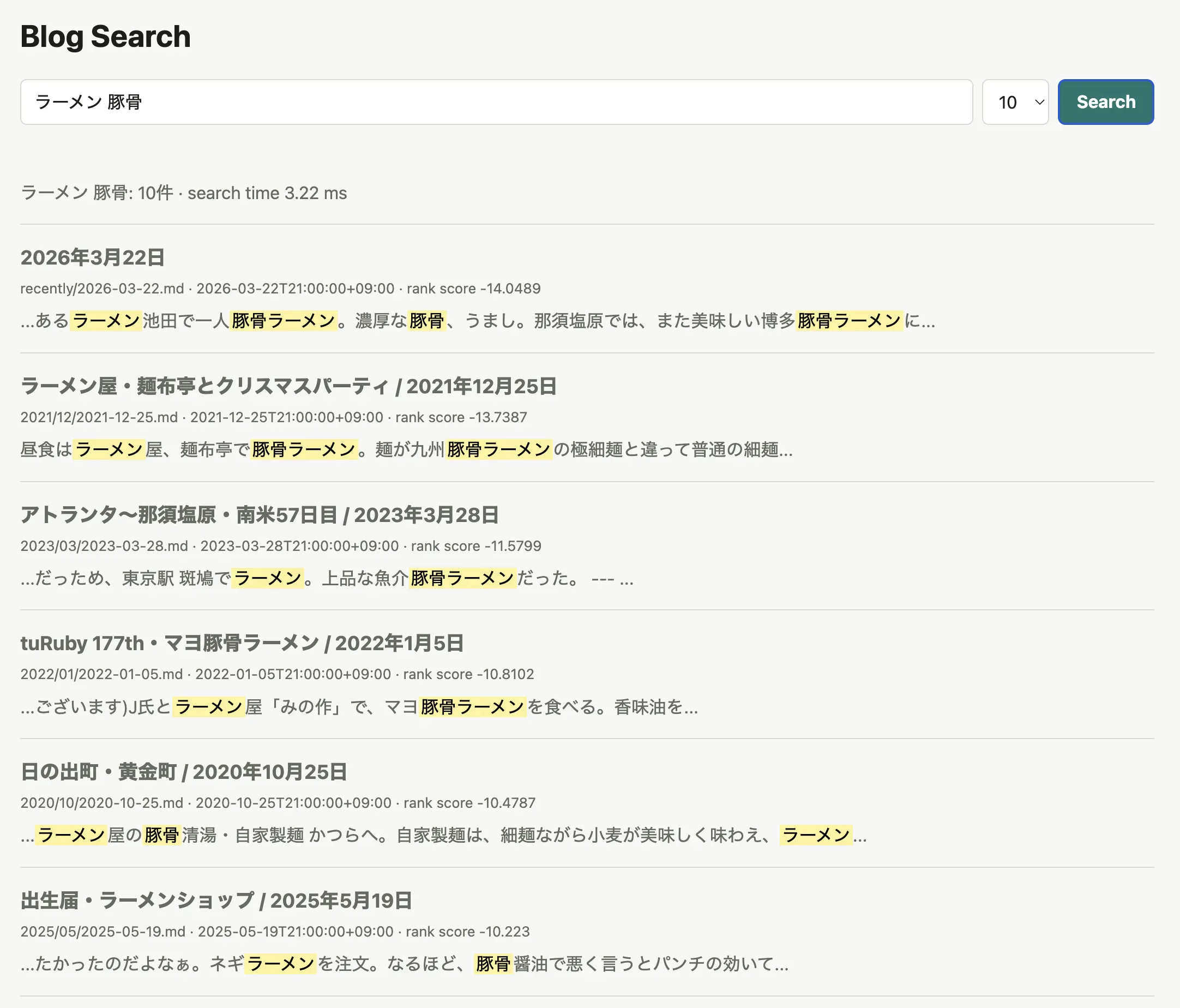
SQLite, DuckDB などでカジュアルに日本語全文検索ができるようになるので、使い所がハマれば便利そうな気がしています。
追記: 形態素解析の第一人者である、Kudo さんよりコメントをいただく、ありがたい。全文検索では点予測による単語分割は、一貫性の無さが不向きと。なるほど〜。
点予測の単語分割は全文検索には不向きです。特に辞書なしだと、文脈依存分割が避けられず検索漏れのリスクが増えます。拙書の形態素解析本に解説あります。
文脈依存性とは、例えば「形態素解析」というフレーズの分割が、その前後文脈に左右されず、一意に決まることを指します。クエリの分割が文書中で再現されることが重要であり、Unigram言語モデルはこの条件を満たします。精度は犠牲になるものの、一貫性が保証されます。

